BlogReaper的第一版本的开发基本上已经完成,这里记录一下前端开发的技术
项目简介
BlogReaper中文名为博客收割机,其实质上是一个高级的在线RSS阅读器,通过添加自己感兴趣的RSS源,可以正在这里分类浏览感兴趣的信息,第一时间阅读感兴趣的信息,而不需要到各个网站分别浏览。
需求
在开发一个项目之前,必须要先确认需求,明确开发方向。
基本功能
首先,来确认一下BlogReaper需要的基本功能,也就是第一个版本必须要有的功能:
- 首页展示热门博客/新闻信息流
- 浏览用户关注的博客信息流
- 用户管理自己的阅读源
- 添加热门阅读源
- 添加自定义博客源(RSS和Atom(Hexo)格式)
- 对阅读源进行分类
进阶功能
这次项目的第一个版本的开发周期比较短,一些设想的功能只能留给下一个版本实现:
- 标记已读/未读信息
- 收藏指定信息到指定的收藏夹
- 稍后阅读功能
- 支持添加自定义链接
- 开发Chrome插件
- 提供简单列表、详细列表、卡片等阅读视图
- 列表进行简单筛选(按时间/热度/综合排序、只显示未读)
- 在阅读源中进行搜索
- 分类搜索、时间筛选
- 社交社区化功能(暂时搁置,社区化功能和微博知乎那些大同小异,如果单纯工具化就不需要以下功能)
- 对于某些博客/新闻文章的评论(类似于微博转发的形式)
- 可以对评论进行回复
- 展示用户关注的阅读源以及分类信息流(可以选择公开或者私有)
- 用户关注系统
- 用户关注的用户评论信息流
- 站内私信功能
- 对于某些博客/新闻文章的评论(类似于微博转发的形式)
技术栈
基本框架:
Vue 2UI组件库:
iview 3网络库:
Vue Apollo 3用户授权系统:
Violet 2
Vue
之前已经开发过很多基于Vue的网站了,比如XMOJ,Violet 2,Coffee以及正在开发中的Violet 3。这次依旧是使用Vue作为前端开发的基本框架,如果有机会的话其实还是想用一下React或者Angular的,但是由于时间仓促,只能用比较熟悉的Vue了
项目结构
1 | . |
项目模块
这是一个很平常的Vue项目,其项目结构和一般的Vue项目也是大同小异。在各个视图当中,把一些可以复用或者功能相对独立的组件从视图中抽离开来,成为组件。
根据需求,将其分为两个基本的页面,分别实现不同的功能
- 首页
- 展示热门阅读内容列表
- 显示阅读源
- 显示时间
- 显示标题
- 显示内容简介
- 显示图片
- 展示热门阅读源列表
- 展示热门阅读内容列表
- 个人页
- 添加阅读源
- 展示稍后阅读内容列表
- 展示订阅源列表
- 展示订阅源内容列表
- 展示分类
- 管理订阅源
GraphQL
和之前的一些项目不同的是,这次的项目使用了Vue Apollo取代了之前的axios,使用了GarphQL作为前端和后端之间通信的规范。
后端使用了graphql-playground直接把API和数据结构用页面展示了出来
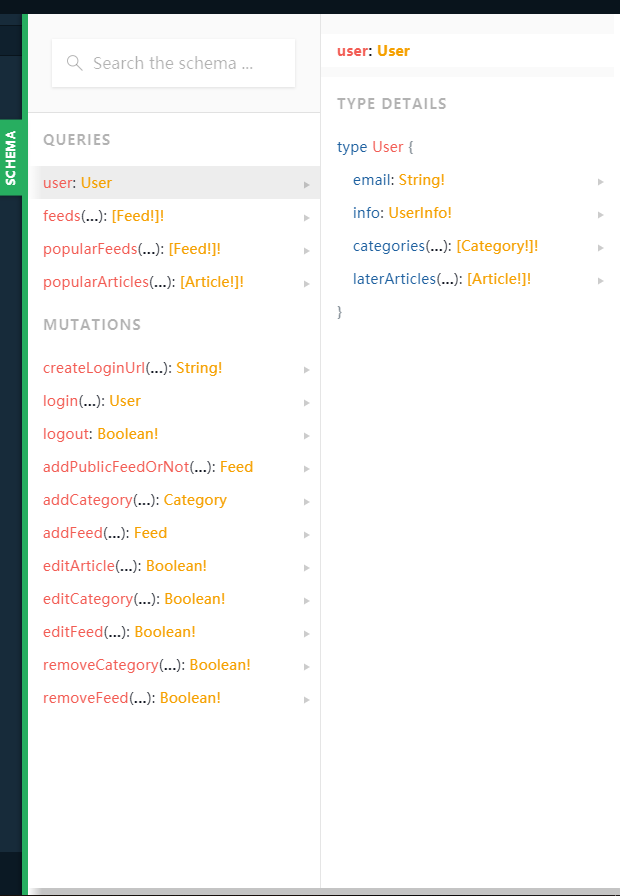
并且还可以在页面上直接测试API,极大地方便了前端的开发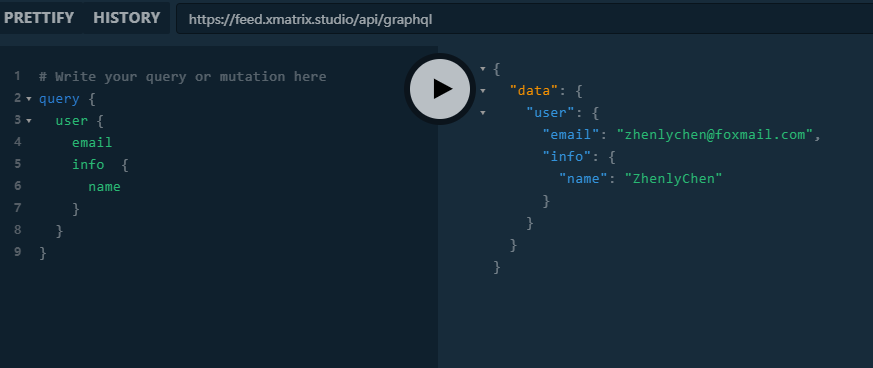
Apollo
在Vue里面,则使用了vue-apollo作为发起GraphQL请求的库。
为了开发的方便,把API部分封装到一个对象里面
1 | const userService = require('./modules/user.js') |
下面是一个获取文章信息的API
1 | // user.js |
所有的API请求都通过wrapper这个函数,对API请求进行统一的管理
调用方法:
1 | await this.$service.feed.getByPublicId.call(this, { |
把this和参数以及成功或者失败的回调传递,然后就可以对这个API进行请求并且在回调函数中处理结果。
使用GraphQL,可以更加灵活地向后端请求资源。获取需要的数据字段,或者对数据做简单的筛选,都可以通过改变请求的结构体实现,而后端不需要改动任何的代码。
1 | // 根据关键字搜索Feeds |
以上的两个不同功能的请求都是基于下面这一个API
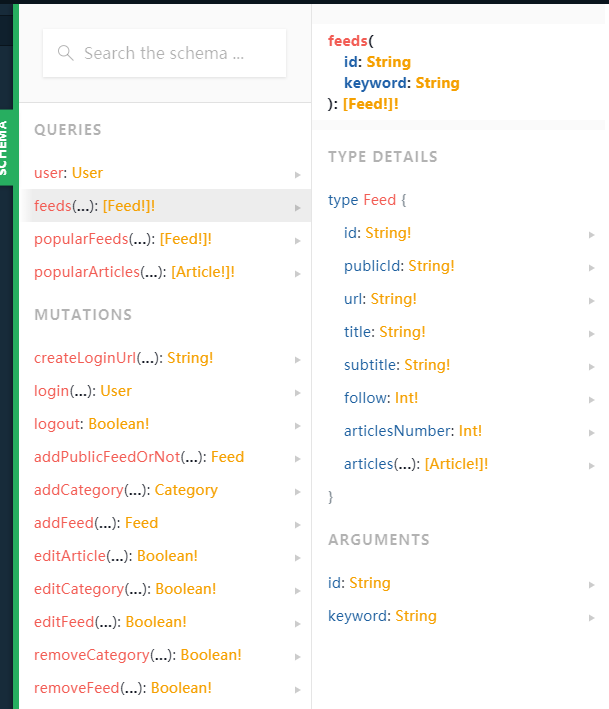
可以看到,对于同一个资源的请求,可以使用不同的筛选条件id或keyword
前者对于每个文章只获取title和url,后者则获取整个文章的具体信息,获取不同的结构的信息。
用户授权系统
最后提一下这里用到的用户授权系统
这次项目依旧使用了Violet 2作为用户系统,Violet是我们团队2017年1月开始开发的一个基于Oauth2用户中央授权系统,使用一个账号,可以登陆我们团队开发的多个项目(XMOJ(已废弃),Coffee内容管理系统,IceCream博客系统,Bug大逃杀类网络游戏),现在又加多了一个BlogReaper。
Violet登陆模式类似于QQ登陆,只需要跳转到Violet页面登陆,然后根据返回的授权码,BlogReaper就可以获取用户的基本信息。对于用户的邮箱认证、密码、头像、基本信息的管理也可以完全托管于Violet
本次基于的2.0版本是于2017年底完成的,如今Violet进入了3.0的迭代进程,3.0将对开发者更加友好,并且提供更安全和方便的认证方式。

