来源于网上一份 60000 个数字图片的训练集以及 10000 个图片的测试集
使用一份来源于网上 60000 个数字图片的训练集以及 10000 个图片的测试集,通过 BP 神经网络识别手写数字
🚀 代码: Github
数据集
http://yann.lecun.com/exdb/mnist/
解析数据集

这一份数据集并不是我们常见的格式,而是根据他定义的特定的格式以大端模式存储的二进制文件
因此我们需要先解析
标签数据集
1 | TRAINING SET LABEL FILE (train-labels-idx1-ubyte): |
首先第一个 byte 是一个 Magic number,第二个 byte 是这个集合里面的数据项个数
然后接下来的 byte 就是对应的图片所对应的正确数字
图片数据集
1 | TRAINING SET IMAGE FILE (train-images-idx3-ubyte): |
和标签数据集一样,第一个 byte 是一个 Magic number,第二个 byte 是这个集合里面的数据项个数
第三个和第四个则是一张图片的宽度和高度
接下来就是以一位数组存储的图片信息,每个图片占据(28*28)个 byte
通过解析这些数据,我们可以得出图片和对应的标签

顺便一提,有些写得是真的难以识别
BP 神经网络
BP 神经网络是一种按误差反向传播(简称误差反传)训练的多层前馈网络,其算法称为 BP 算法,它的基本思想是梯度下降法,利用梯度搜索技术,以期使网络的实际输出值和期望输出值的误差均方差为最小。
基本结构
这里采用了三层结构的全连接的 BP 神经网络
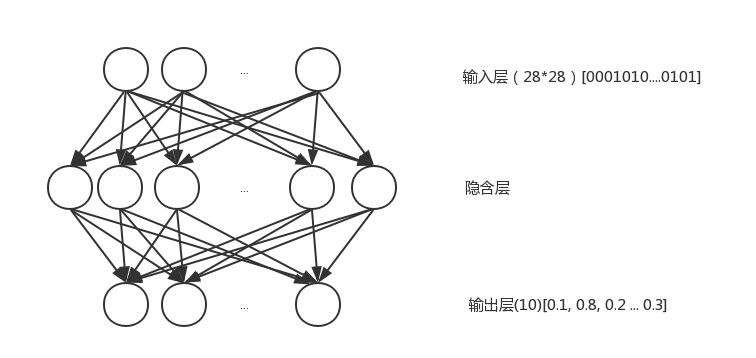
输入层
首先输出层有28*28个节点,分别对应图片的28*28的像素
如果当前像素为背景像素,那么就为0,如果是数字所在的像素,那么就为1
隐含层
隐含层的节点数是自定义的,一般情况下,节点数越多,每次训练中误差的收敛的速度就快,但是同时每一次训练所花费的时间也会线性增长。
在本机的测试中
在64个节点的时候,5次训练之后其均方差达到了0.0101的水平,而对于测试集的识别率达到了92.51%(+-0.1%)
在144个节点的时候,3次训练之后其均方差达到了0.0081的水平,而对于测试集的识别率达到了94.86%(+-0.1%)
在200个节点的时候,3次训练之后其均方差达到了0.0076的水平,而对于测试集的识别率达到了95.29%
在256个节点的时候,3次训练后对于测试机的识别率可以达到96.68%,多重训练之后,甚至可以达到98%以上
输出层
输出层输出的是一个 10 位大小的数组,表示这次输出是某个数字的概率,选择最大的一个作为结果输出
基本过程

BP 神经网络其核心在于Sigmoid 函数,通过误差值更新当前的权值,使用训练集多次迭代之后对测试集进行测试,将图片识别成相应的数字
这里使用到的是单极性 Sigmoid 函数
$f(x) = \frac{1}{1+e^(-x)}$
误差反传使用以下两个公式
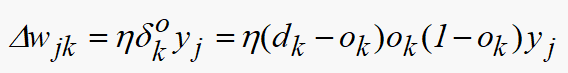
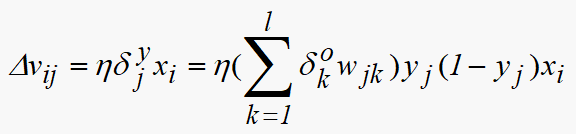
其具体算法可以参考上面的流程图
基本上可以分以下过程:
初始化
1 | rand.Seed(time.Now().Unix()) |
这里使用了书本上所推荐的$[-2.5/F, 2.5F]$的均匀分布的随机初始权值,F 为输入端的个数
计算各层输出
1 | // 初始化输入层 |
这里对于 Sigmoid 函数的值的更新增加了一个陡度因子,防止输入的数据过大导致函数过饱和而得到一样的值,而且可以提高在平坦区时候的收敛速度
调整权值
1 | // 计算预期输出 |
在计算误差的时候,引入了一个动量因子,防止训练过程中发生震荡从而收敛缓慢。从前一次权值调整量中取出一部分迭加到本次权值调整量中,动量项反映了以前积累的调整经验,对于 t 时刻的调整起阻尼作用。当误差曲面出现骤然起伏时,可减小振荡趋势,提高训练速度。
在设置预期输出的时候,没有使用 0 和 1,而是采用 0.999 和 0.001,设置比期望输出数相对小一点,避免了学习算法不收敛
根据误差,我们来调节权值,达到反向调节的作用
测试
由于参数的不同可以导致不同的识别率和结果,下面的测试统一使用以下的参数
1 | // 隐含层节点数(推荐值: 64 - 256) |
训练测试
使用 144 个隐节点使用 60000 个训练项训练三次后对于 10000 个测试项进行测试
1 | $ go run .\main.go .\train.go |
三次测试的平均识别率有94.72%
手写识别测试
在前端网页使用 canvas 绘制数字,然后转为 base64 传给服务器
服务器收到 base64 后将其转换为 png 格式的图片,图片的大小为 140*140
我们将图片划分成 28*28 的小块,如果当前区域存在数字像素,那么这个小块就设置为 1,否则为 0
将 28*28 的数据输入之前训练好的模型中,然后服务端返回结果显示在前端

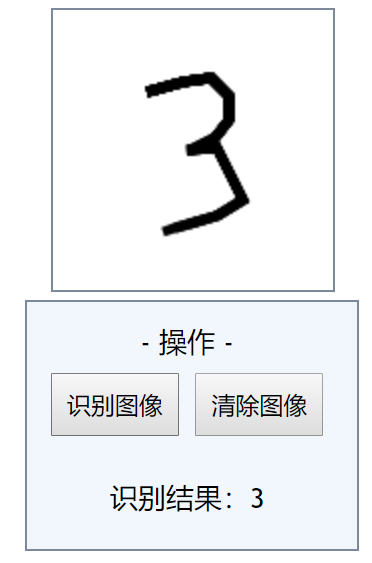
对于一些比较清晰而且大小适中的数字,识别率还是不错的

